Fonctionnement
Implémentation technique
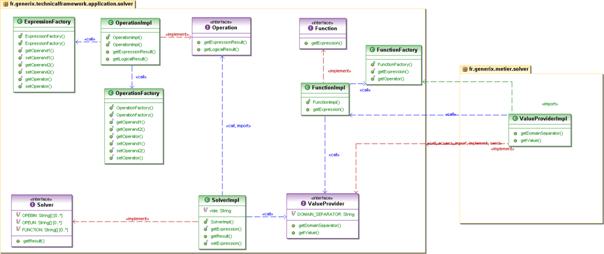
Le socle technique d’ACE (technicalframework) propose cette nouveauté fonctionnelle aux couches supérieures (métier et application). Le pilotage est réalisé dans les ViewLink, XDME est lui aussi impacté par cette nouveauté.
Afin de répondre à une utilisation la plus large et la plus souple possible, il a été décidé d’appliquer un principe équivalent aux resolver de requêtes, à savoir :
- Le socle propose l’implémentation technique et la modification du schéma (configuration.xsd)
- Le socle définit les règles sur les couches abstraites et sur les interfaces
- Le métier gère la spécialisation de ces resolver et fournit les références vers la couche application (dans le fichier de configuration)
Dans le cas présent, nous parlerons de « resolver de valeurs » ou de « fournisseurs de valeurs ».
L’implémentation réalisée ce jour permet de résoudre principalement 3 types de valeurs :
- Des valeurs de paramètres (PPE) de la table PARAV,
- Des valeurs liées au paramétrage général (table PEV)
- La valeur du CODSOC physique des tables (couple entité, segment optionnel : table MEV).
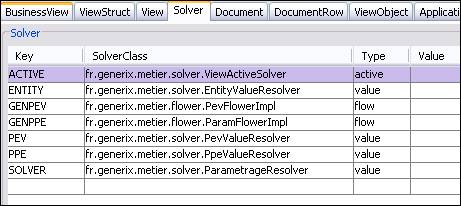
Extrait du schéma : ViewLink
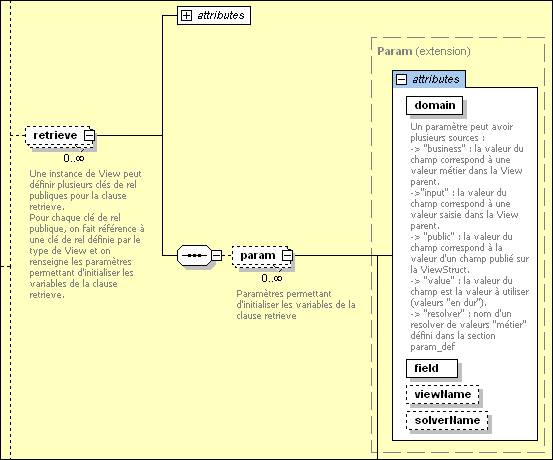
Le nouvel attribut est nommé « solverName » car il s’agit d’un nom logique (non directement la référence à la classe Java).
Extrait du schéma : Param_def
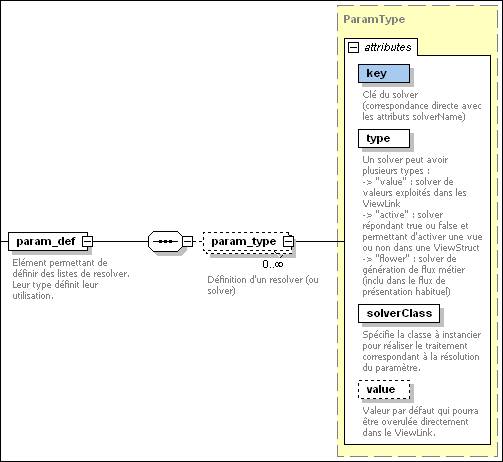
Une sous-section de la section « application » permet de définir de manière globale les solver de tout type que l’on va exploiter dans la configuration. C’est une manière de généraliser leur exploitation avec un seul écran dans XDME.
Description des différents attributs :
- name : le nom « logique » du solver
- type : value ou active pour le cas qui nous préoccupe dans ce document
- solverClass : la référence à la classe Java
- value : la valeur par défaut (aucune utilisation ou exploitation pour le moment, cet attribut est réservé à un usage ultérieur).
Dans XDME, cette section est définie sous la forme d’un onglet général :
Packages
L’implémentation au niveau de socle se fait principalement dans les classes gérant les ViewLink, ainsi que dans le package :
- fr.ACE.technicalframework.application.solver
- on trouve ici un ensemble de classes abstraites et d’interfaces qui permettent d’étendre le développement vers la couche métier.
Dans la couche métier, les différents solver livrés en standard se trouvent dans le package suivant :
- fr.generix.metier.solver
Exemple d’utilisation opérationnelle
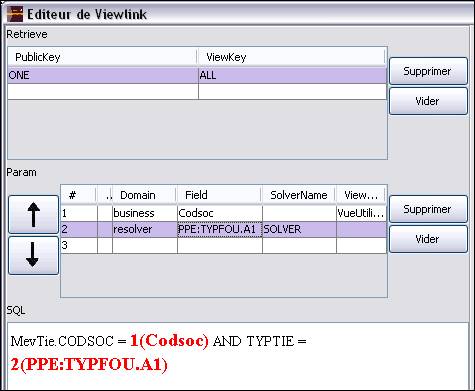
Une liste de clients comporte deux paramètres obligatoires sur la table principale (table TIE) :
- Le code société : champ CODSOC
- Le type de tiers : champ TYPTIE
On a donc une requête définie dans la configuration qui, en plus de prendre ces champs là en compte, va comporter des paramètres optionnels (entourés de crochets : []).
La requête ressemble à ceci :
MevTie.CODSOC = ? AND TYPTIE = ? [ AND SIGTIE LIKE ?] [ AND NOMTIE LIKE ?] …
Dans XDME, le passage de paramètres ressemble à ceci :
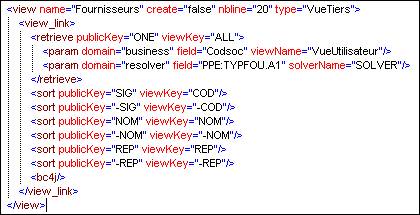
Vue XML de cette partie de la configuration :

Syntaxe complète
Toutes les valeurs à exprimer doivent être saisies en majuscule, il s’agit d’un choix de développement.
Définition des espaces de nommage
Les espaces de nommage d’ores et déjà disponibles sont les suivants :
- PEV : Le paramétrage de la fonction - typé "événement" ou "tiers" - correspondant à la table PEV
- PPE : les paramètres associés à la cible de paramétrage, usuellement nommés PPE (Paramètres Pour Evénements)
- MEV : résolution des valeurs de CODSOC_PHY
Exemples de valeurs opérationnelles :
- PPE :TYPCLI.A1
- PPE :TYPMAG.A2
- PPE :PACPRO.N1
- PPE :RECCTS.L1
- PEV :TYPTIE
- MEV :PRO
- MEV :TIE.CLI
Liste des valeurs publiées pour les PPE (le nom est séparé par un « . ») :
- A1 à A3
- N1 à N5
- M1 et M2
- D1 à D3
- L1 (correspond au champ LIBPAR de la table PARAV)
Liste des valeurs (équivalent aux noms de champs) publiées pour le paramétrage de la fonction (PEV) :
- ACHVTE : Code Achat/Vente
- TYPEVE : Type d'événement
- CODETA : Code état géré de l'événement
- VALETA : Code état validé de l'événement
- SOLETA : Code état soldé de l'événement
- TYPTIE : Type de tiers géré
- ACHVTO : Code Achat/Vente origine
- TYPEVO : Type d'événement origine
- ETAEVO : Code état de l'événement d'origine
- ACHVTS : Code Achat/Vente source
- TYPEVS : Type d'événement source
- CODETT : Nature de l'événement
|
|
Attention Les valeurs spécifiées sont sensibles à la casse, « PPE:TYPMAG.A1 » n'est pas équivalent à « ppe:typmag.A1 » par exemple. La casse doit donc être respectée. |
Fonctions utilisables
Il peut être intéressant dans certains cas de fournir la possibilité de réaliser directement des calculs sur les valeurs. A titre d’exemple, on peut noter que la clé d’un texte libre (table TXT) est une concaténation de plusieurs champs avec remplissage par des « 0 ».
Certaines fonctions sont donc implémentées pour répondre à ce besoin. Par la suite, de nouvelles fonctions pourront être développées au besoin par ACE Editeur.
Extensions des espaces de nommage :
- Les fonctions : DECODE, CONCAT, INSTR, SUBSTR, RPAD, LPAD, LOWER et UPPER dont le fonctionnement est relativement similaire à la définition Java ou SQL.
- La possibilité d'exploiter 2 espaces de nommage supplémentaires : VLB et VLP afin de récupérer des valeurs provenant des espaces de nommage "public" et "business". Dans le cas des paramètres "business", on ne peut prendre en compte à ce jour que le niveau immédiatement supérieur à la vue courante. Exemple : VLB:Codsoc
- L'espace de nommage MEV permet de récupérer le code société physique (champ CODSOC_PHY) pour un couple entité/segment donné. Par exemple : MEV:PRO ou MEV:TIE.FOU
Note sur l’espace de nommage des PPE
Lorsque qu’aucune valeur de champ n’est demandée pour un PPE donné, le fournisseur de valeur renvoie TRUE ou FALSE. Par exemple, si le PPE TYPFOU est positionné, la syntaxe suivante renverra TRUE :
- PPE:TYPFOU
La valeur renvoyée est en majuscule, la casse ici aussi est fondamentale.