Généralités
Architecture
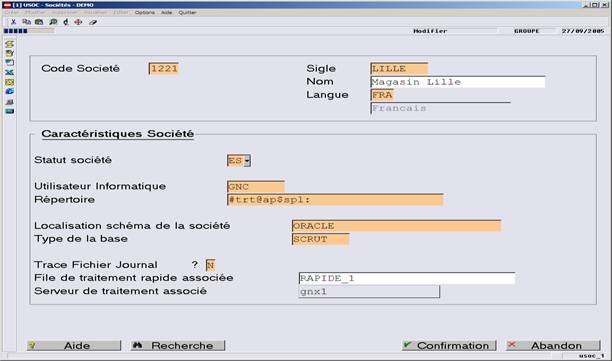
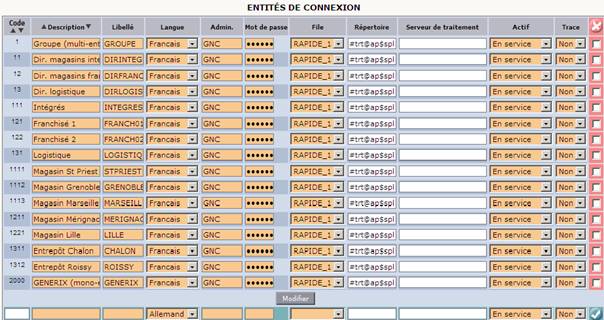
L’architecture dite « Multi Serveurs ACE » se décompose au minimum de deux serveurs de traitement ACE et d’un serveur de données. Elle est administrée grâce à ACE MANAGER (depuis sa version 3.1).
Dans cette architecture, tous les serveurs de traitement doivent être équipés du même type de système d’exploitation.
Dans un tel environnement, il existe toujours un serveur « Maître», les autres serveurs étant « Non maître ».
Le serveur Maître sert de référent pour se connecter et administrer l’ensemble des éléments de l’architecture multi serveurs. Pour exemple, certaines fonctionnalités d’ACE Manager liées à la gestion de la base de données notamment, ne sont accessibles qu’au travers de l’environnement Maître.
|
|
Pour en savoir plus sur la mise en place d’une telle architecture, consultez la documentation de référence « Mise en œuvre du mode multi serveurs de traitement ». |
Principes techniques
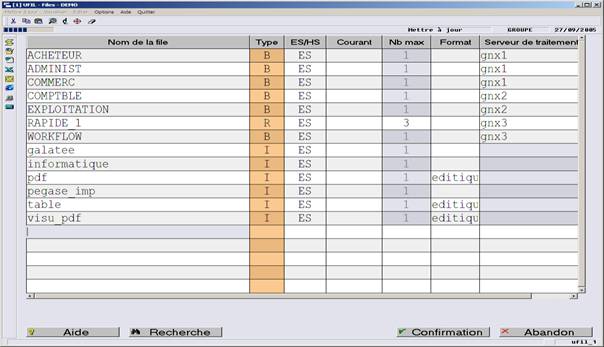
Les répertoires ap$spl et ap$log sont partagés et accessibles depuis tous les serveurs de traitement..
Il n’est pas possible de faire un « repository » de Multi serveurs ACE.
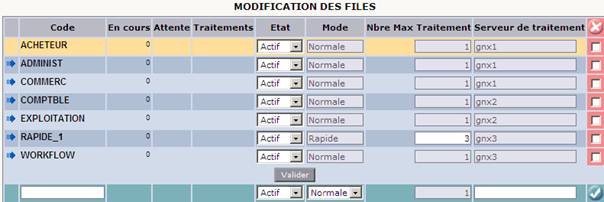
Le champ « srvtrt », apparaissant dans les tables UT_SOC et UT_FIL, contient un alias du serveur de traitement à utiliser ; la définition de l’alias étant également présente dans la table UT_CONFIG.
|
|
Attention Pour les serveurs 64 bits, cette fonctionnalité est disponible à partir des versions d’Oracle 10.1.04. |